
Hamza T.
Back-end Django developer

Software web developer who has around 5 years of experience worked with a lot of stacks which Python/Django is the major. Hamza is hard worker and team player who is proficient in an array of web development tools.
Skills
- Python
- Django
Experience
Informational technologies and services, Germany
Senior Software Engineer
June 2021 to December 2021
Stack:
- Python
- Django
- Celery
Responsibilities:
- Preparing endpoints for dashboard
- Developing of admin page for creating dynamic datasets
Internet technologies, Turkey
Big Data Engineer - Team Lead
March 2019 to June 2021
Stack:
- AWS EMR
- Airflow
- AWS Kinesis
- AWS Lambda
- AWS S3
- AWS EB
- AWS EKS (kubernetes)
- AWS Elasticache
- Akka
- Scala
- Node.js
- Python
- Elasticsearch
- Apache Spark
Responsibilities:
- Developing components for search API
- Leading the team
- Maintaining the apache spark jobs
- Working closely with product manager to distribute tasks to developers
Telecommunications, Turkey
Software - Data Engineer
October 2017 to March 2019
Stack:
- Spark
- Node.js
- Flask
- Django
Responsibilities:
- Web Services
- Recommendation Engine
- ETL Processes
- Standalone Cluster Management
Education
Bachelor's degree in Computer Engineering, Istanbul Technical University
September 2012 to January 2018
Turkey
Portfolio
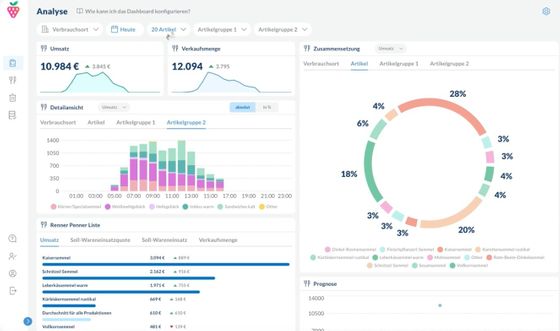
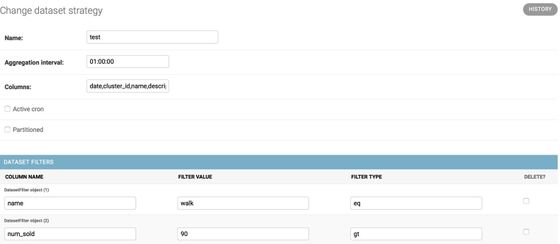
I was a backend developer and I was responsible for creating celery jobs, maintaining API endpoints. The team size was 5 people, 3 of them were backend developers, 1 frontend developer and 1 machine learning engineer. I worked on the data processing and dataset preparation side mostly.
The dashboard is created to make analyses about food production, forecasting, waste information along with their insights. Celery jobs are created to prepare a dataset and enrich it with additional information like weather, holidays etc.
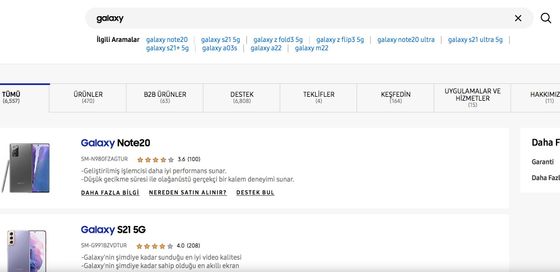
I was responsible for maintaining existing features (APIs, jobs, queues etc.), helping to create a roadmap, developing and planning the roadmap items, make regular meetings with team members. The team consisted of 4 developers, 1 tester, 1 product manager and I was the tech lead of the team.
Search result pages are very important for e-commerce websites. Most of the users tend to buy after they make a search. So the quality of the result page is very important and the user needs to see the most relevant results. Relevant products do not just depend on string matches but also depend on user clicks and purchases. Classical search engines are based on tf-idf (term frequency) and sometimes it fails on keywords that are not included in the product information. So tf-idf needs to be combined with the probabilistic model.
The project consists of 3 main parts: data collection, API’s and data processing jobs. Data collections consist of combinations of different queues. Each queue has different purposes like data validation, death letter, product update etc. After product information changes on the website, the search engine database should be updated as soon as possible with current information. API consists of the main search API which prepares results and microservices that help the main API. Jobs are responsible for processing raw data, preparing machine learning models and preparing insights about data.
Main search API is built with capabilities of load balancing, auto-scaling, machine learning models are created and models are served under microservices. Elasticsearch and Mysql are used as databases.
Request Hamza's Rate
Find us on:
