
На этой радостной ноте выполнение JavaScript завершается, и libUV проверяет, есть ли какие-то watcher, которые могут сработать, то есть, есть ли какие-то внутренние обработчики. Если их нет, то завершается весь процесс Node.js, завершается весь событийный цикл. Но, в данном случае, один такой watcher, а именно обработчик на порту 3000 был поставлен. Именно поэтому процесс Node.js не завершится, а временно заснет. Он будет спать до появления какой-нибудь причины ему проснуться, например, до появления новых событий ввода-вывода.
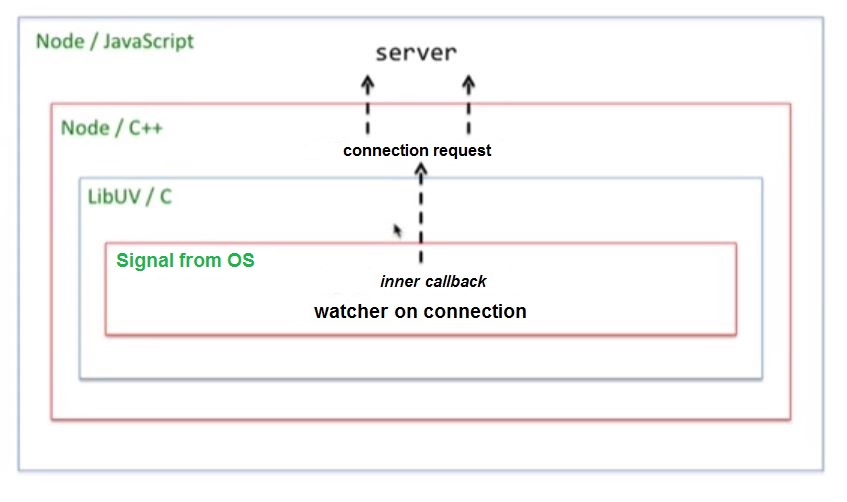
Рано или поздно такое событие, скорее всего, произойдет. Появится сигнал из операционной системы, что кто-то присоединился к порту 3000, внутренний watcher libUV вызовет соответствующий callback, тот, в свою очередь, передаст сигнал библиотеке libUV, потом он придет в Node.js. Обертка Node.js тут же сгенерирует событие connection и примется разбирать то, что нам присылают. Далее, если в процессе анализов данных установлено, что это http-запрос, то будет сгенерировано событие request и, наконец то, сработает этот обработчик:
server.on('request', function(req, info) {
if (req.url == '/') {
fs.readFile('index.html', function(err, info) {
if(err) {
console.error(err);
res.statusCode = 500;
res.end("A server error occurred ");
return
}
res.end("info");
});
} else { /*404 */ }
});
Если получилось так, что url вот такой:
if (req.url == '/') {
то при помощи libUV инициируется считывание обработчика.
Мы отправляем команду в libUV, а на текущем моменте JavaScript заканчивает работу. Все, request–событие обработано. Так как JavaScript закончил выполнение, и есть внутренние обработчики libUV, то процесс не прерывается, а снова переходит в состояние спячки. Из нее его могут вывести события. Какие?
Первое – это новый запрос, а второе – это завершено чтение файла или какая-то ошибка возникла, это не так важно для нас сейчас. Когда что-то из этого произойдет, то будет вызван соответствующий JavaScript callback.
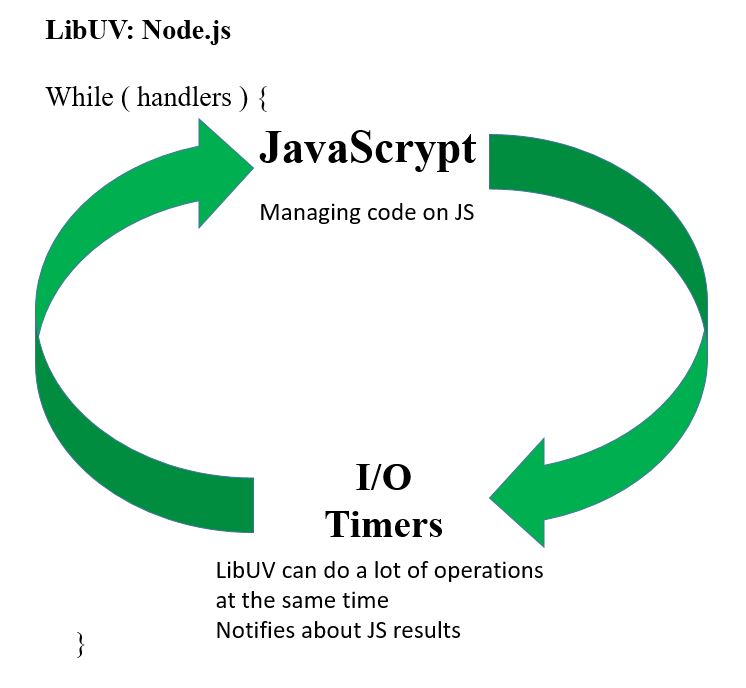
Получается, что наш код на языке JavaScript выступает в роли главного рулевого. Он говорит libUV: инициируй какой-то процесс, например, чтение файла, или получай соединение на таком-то порту. libUV умеет это правильно передать операционной системе. Дальше операционная система занимается всяческими делами, а libUV ждет, пока та ответит. Когда операционная система ответит, то libUV опять же вызывает наш JavaScript код, который разрешит эту ситуацию, возможно, инициирует какие-то новые процессы ввода-вывода, и дальше процесс опять переходит в состояние спячки. И так по циклу.
Казалось бы, все более-менее ясно. На самом деле, есть еще некоторые нюансы. Например, представим себе, что первое событие, которое здесь произошло, это мы получили новый запрос. Управление переходит в JavaScript, и вдруг, во время его выполнения происходит завершение чтения файла, срабатывают внутренние обработчики libUV, но JavaScript то занят! Поэтому, внутреннее событие libUV стало в очередь. Получается так, что пока JavaScript занят каким-то делом, внутри libUV может возникнуть целая очередь событий, которые ожидают обработки. Когда JavaScript закончит работу, он посмотрит в эту очередь, возьмет из нее первое событие и обработает. Потом опять посмотрит в очередь, опять возьмет, обработает и т.д.
Обработка внутренних событий libUV будет осуществляться последовательно. Например, если мы обрабатываем запрос для Джона, а в это время завершилось чтение файла для Мэрри, Питера и Илона, то есть, возникло 3 новые внутренние события, то они стали в очередь, и будут обработаны последовательно по мере освобождения интерпретатора JavaScript.
При этом, несмотря на то, что очередь событий одна, путаница никогда не возникнет, потому что, когда запускается соответствующий callback, то информацию о том, что это за запрос, он получает из замыкания JavaScript, то есть, если запустился callback для Илона , то будет req для Питера. Для Мэрри callback запустился, то это уже другая функция, другое замыкание соответственно. Будет продолжаться обработка, будет ответ прислан уже Мэрри.
С другой стороны, получается так, что, для того чтобы работа сервера была наиболее эффективной, JavaScript должен выполняться очень быстро, то есть, чтобы никакие новые события не накапливались и не ждали. Что будет, если JavaScript почему-то затормозит? Например, если есть какая-то тяжелая вычислительная задача, а Node.js занят, события накапливаются. Такая ситуация называется
«Event loop starvationn». При этом, обработка всех клиентов, которая от них зависит, притормозится, что, конечно же, не очень то хорошо. Для того, чтобы обойти эту проблему тяжелого вычисления, обычно выделяют либо в отдельный процесс, либо в отдельный поток, либо запускают сам сервер Node.js в режиме множества процессов. Например, это можно делать, использовав встроенный модуль cluster, но и не только. Еще один вариант – это разбить тяжелую вычислительную задачу на части, например, часть ответа можно сгенерировать в функции
server.on('request', function(req, info) {
if (req.url == '/') {
fs.readFile('index.html', function(err, info) {
if(err) {
console.error(err);
res.statusCode = 500;
res.end("A server error occurred ");
return
}
res.end("info");
});
} else { /*404 */ }
});
Потом через setTimeOut 10 мс отложить генерацию следующей части ответа и т.д. При этом получится, что, с одной стороны, работа выполнена в сумме такая же, но в выполнении JavaScript разрывается. В промежутке между этими вычислениями сервер может делать что-то еще, обрабатывая других клиентов. Так или иначе, все эти решения добавляют сложности, поэтому Node.js используется, в первую очередь, там, где тяжелых вычислений не нужно и где требуется обмен данными. Практика показывает, что это большая часть задач связана с веб-разработкой.
Итак, подведем итоги.
- Сердцем Node.js является библиотека libUV. В этом и сила, и слабость сервера Node.js.
- С одной стороны, libUV позволяет делать много операций ввода-вывода одновременно, то есть, наш JavaScript-код может инициировать операцию и дальше заниматься своими делами. Таким образом, множество операций ввода-вывода могут обрабатываться операционной системой одновременно, а JavaScript будет пересылать данные от одного клиента к другому, от базы данных к клиенту и т.д. Просто и эффективно.
- С другой стороны, это все требует асинхронной разработки. Не readFileSync a readFile. Принятая в Node.js система callback, с одной стороны, достаточно проста, а с другой стороны, она все равно сложнее, чем просто последовательные команды синхронной разработки. Кроме того, так как JavaScript процесс должен обрабатывать кучу событий, то желательно, чтоб он не ждал, а делал все быстро для того, чтобы очередь событий не накапливалась. Эту особенность работы Node.js стоит иметь в виду с самого начала разработки веб-приложения. Потому что, казалось бы, какие у нас сложные вычислительные операции, что может заблокировать JavaScript? А, например, parsing большого json или подсчет md5sum большого закаченного файла.
Эти задачи влияют на производительность сервера еще до того, как JavaScript который выполняется съест все 100% процессора. То есть, Node.js может кушать 20%, но работать недостаточно эффективно просто из-за того, что пока JavaScript занят, другие задачи, даже те, которым нужны другие ресурсы, скажем, база данных, не могут продолжить выполнение. Для того, чтобы как то защититься от этого, обычно запускают Node.js-приложения в режиме множества процессов.
Дальше больше интересного. Stay tuned!
Код урока вы можете найти по ссылке.

Материалы взяты из данного скринкаста
We are looking forward to meeting you on our website soshace.com