

Всем привет! Тема этого занятия: Потоки данных в Node.js. Мы постараемся разобраться в этой теме более подробно, поскольку, с одной стороны, так получается, что потоки в обычной браузерной JavaScript разработке отсутствуют, а с другой стороны, уверенное владение потоками необходимо для грамотной серверной разработки, поскольку поток является универсальным способом работы с источниками данных, которые используются повсеместно.
Можно выделить два основных типа потоков: первый поток –
stream.Readable
Это встроенный класс, который реализует потоки для чтения. Как правило, сам он не используется, а используются его наследники, в частности, для чтения с файла есть fs.ReadStream, для чтения с запроса посетителя при его обработке есть специальный объект, который мы раньше видели под именем req – первый аргумент обработчика запроса.
Stream.Writable
Это универсальный способ записи. Сам stream.Writable обычно не используется, но используются его наследники: fs.WriteStream и res.
Есть и некоторые другие типы потоков, но наиболее востребованы эти два и производные от них.
Самый лучший способ разобраться с потоками – это посмотреть, как они работают на практике. Поэтому сейчас мы начнем с того, что используем fs.ReadStream для чтения файла. Создадим файл fs.js:
var fs = require('fs');
// fs.ReadStream nherits from stream.Readable
var stream = new fs.ReadStream(__filename);
stream.on('readable', function() {
var data = stream.read();
console.log(data);
});
stream.on('end', function() {
console.log("THE END");
});Итак, подключаем модуль fs и создаем поток:
var fs = require('fs');
var stream = new fs.ReadStream(__filename);Поток – это JavaScript-объект, который получает информацию о ресурсе, в данном случае путь к файлу (__filename), и который умеет с этим ресурсом работать. fs.ReadStream реализует стандартный интерфейс чтения, который описан в классе stream.Readable. Давайте рассмотрим более подробно.
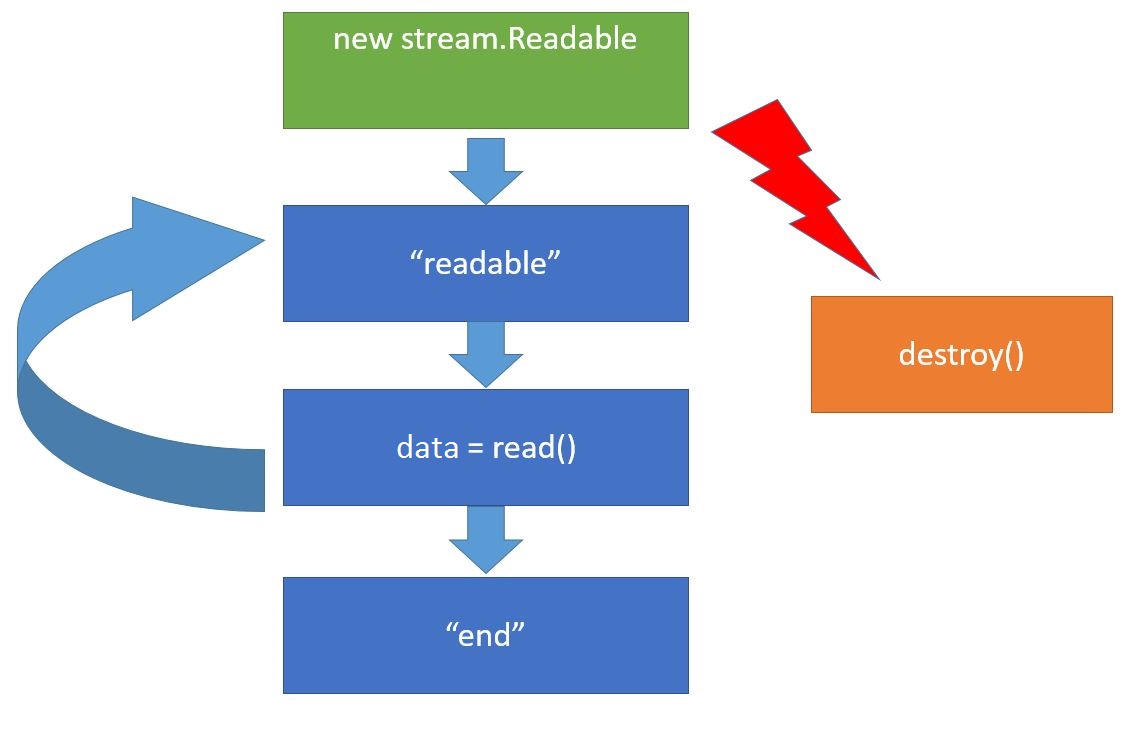
Когда создается объект потока (new stream.Readable) , то он подключается к источнику данных, в нашем случае это файл, и пытается начать из него читать. Когда он что-то прочитал, то имитирует событие “readable”. Это событие означает, что данные просчитаны и находятся во внутреннем буфере потока, который мы можем получить, используя вызов read(). Затем мы что-то можем делать с данными (“data”) и подождать следующего “readable”. И так дальше по кругу.
Когда источник данных иссяк, бывают, конечно, источники, которые не иссякают, например, датчики случайных чисел, но размер файла то ограничен, поэтому в конце будет событие “end”, которое означает, что данных больше не будет. Также на любом этапе работы с потоком мы можем вызвать метод destroy() потока. Этот метод означает, что мы больше не нуждаемся в потоке и можно его закрыть, а также закрыть соответствующие источники данных, полностью все очистить.
Теперь вернемся к исходному коду. Итак, здесь мы создаем ReadStream, и он тут же хочет открыть файл:
var stream = new fs.ReadStream(__filename);
но в данном случае, вовсе не означает, на этой же строке, потому что все операции, связаны с вводом-выводом, реализуются через libUV. А libUV устроено так, что все синхронные обработчики ввода-вывода сработают на следующей итерации событийного цикла, то есть, заведомого после того, как весь текущий JavaScript закончит работу. Это означает, что мы можем без проблем навесить все обработчики, и мы твердо знаем, что они будут установлены до того, как будет считан первый фрагмент данных. Запускаем fs.js.
Смотрим, что вывелось в console. Первым сработало событие readable. Оно вывело данные. Сейчас это обычный буфер, но можно преобразовать его к строке, указав кодировку непосредственно при открытии потока.
var stream = new fs.ReadStream(__filename, {encoding: 'utf-8'});Таким образом преобразование будет автоматическим. Когда файл закончился, то событие end вывело THE END в консоль. Здесь файл закончился почти сразу, поскольку он был еще маленьким. Сейчас немного модифицируем пример, сделав вместо текущего файла файл big.html, который находится в текущей директории. Скачайте этот HTML файл из нашего репозитория вместе с остальными материалами урока.
Запускаем. Файл big.html большой, поэтому событие readable срабатывало многократно, и каждый раз мы получали очередной фрагмент данных в виде буфера. Давайте, выведем его длину:
var fs = require('fs');
// fs.ReadStream nherits from stream.Readable
var stream = new fs.ReadStream("big.html");
stream.on('readable', function() {
var data = stream.read();
if (data){
console.log(data.length);
}
else {
console.log('data is null')
}
});
stream.on('end', function() {
console.log("THE END");
});
Запускаем. Эти числа – это длина прочитанного фрагмента файла. Потому что когда поток открывает файл, он читает из него только кусок, а не весь файл, и помещает его в свою внутреннюю переменную. Максимальный размер – это как раз 64 кВ. Пока мы не вызовем stream.Read, он дальше читать не будет. После того, как мы получим эти данные, внутренний буфер очищается и он может прочитать следующий фрагмент, и т.д. Длина последнего фрагмента – 60959 В. На этом примере мы отлично видим важные преимущества использования потоков. Они экономят память. Каков бы большой файл не был, все равно единовременно мы обрабатываем небольшой фрагмент. Второе, менее очевидное, преимущество – это универсальность интерфейса. Здесь мы используем поток ReadStream из файла. Но мы можем в любой момент заменить его на произвольный поток из нашего ресурса:
var stream = new OurStream("our resource");Это не потребует изменения оставшейся части кода, потому что потоки – это, в первую очередь, интерфейс. То есть, в теории, если наш поток реализует необходимые события и методы, в частности, наследует от stream.Readable, то все должно работать хорошо. Это, конечно, только в том случае, если мы не использовали специальных возможностей, которые есть только у файловых потоков. В частности, у потока fs.ReadStream есть дополнительные события.
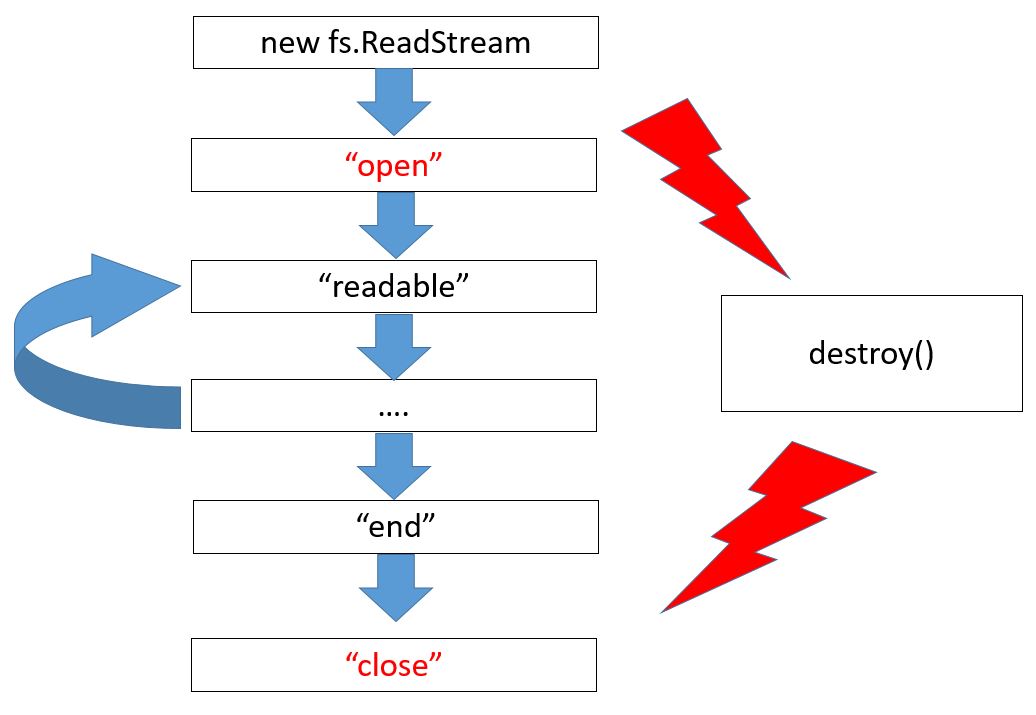
Здесь изображена схема именно для fs.ReadStream, новые события изображены красным цветом. В начале это открытие файла, а в конце – закрытие. Обратим внимание, если файл полностью дочитан, то возникает событие end, а затем close. А если файл недочитан, например, из-за ошибки или при вызове метода destroy, то end не будет, поскольку файл не закончился, но всегда гарантируется при закрытии файла событие close.
И, наконец, последнее по коду, но отнюдь не последняя по важности деталь – обработка ошибок. Например, посмотрим, что будет, если файла нет.
var stream = new fs.ReadStream("noFile.html");Запускаю. Упс! Все упало! Обратите внимание, потоки наследуют от EventEmitter. Ели происходит ошибка, то весь процесс Node.js падает. Это в том случае, если на эту ошибку нет обработчиков. Поэтому, если мы хотим, чтобы в случае чего Node.js вообще не упал из-за исключения, то нужно обязательно поставить обработчик:
var fs = require('fs');
// fs.ReadStream nherits from stream.Readable
var stream = new fs.ReadStream("noFile.html");
stream.on('readable', function() {
var data = stream.read();
if (data){
console.log(data.length);
}
else {
console.log('data is null')
}
});
stream.on('error', function(err) {
if (err.code == 'ENOENT') {
console.log("File not Found");
} else {
console.error(err);
}
});
Итак, для работы с источниками данных в Node.js используются потоки. Здесь мы рассмотрели общую схему, по которой они работают, и ее конкретную реализацию, а именно fs.ReadStream, которая умеет читать из файла.
Код урока Вы можете найти в нашем репозитории.

Материалы для статьи взяты из следующего скринкаста.
We are looking forward to meeting you on our website soshace.com