

Нашим следующим шагом будет использование потоков для работы с сетевыми соединениями. И начнем мы с отдачи посетителю файлов. Если помните, у нас была такая задача: если посетитель запросит следующий url, то отдать ему файл. Создадим файл pipe.js со следующим кодом (для удобства вы можете скачать код нашего урока в репозитории, так как нам понадобиться HTML файл оттуда) :
var http = require('http');
var fs = require('fs');
new http.Server(function(req, res) {
// res instanceof http.ServerResponse < stream.Writable
if (req.url == '/big.html') {
fs.readFile('big.html', function(err, content) {
if (err) {
res.statusCode = 500;
res.end('Server error');
} else {
res.setHeader("Content-type", "text/html; charset=utf-8");
res.end(content);
}
});
}
}).listen(3000);
Пример решения этой задачи без потоков может быть таким: читаем файл:
fs.readFile('big.html', function(err, content) {
когда тот будет прочитан вызываем callback:
function(err, content) {
if (err) {
res.statusCode = 500;
res.end('Server error');
} else {
res.setHeader("Content-type", "text/html; charset=utf-8");
res.end(content);
}
});
дальше при ошибке сообщаем о ней, а если все хорошо, то ставим заголовок, чтобы указать, какой это файл. И записываем содержимое файла в ответ вызовом res.end(content) , который отдает контент и завершает соединение. Это решение в принципе работает, но его проблема – это пожирание памяти, потому что если файл большой, то readFile его сначала считает, а потом вызовет callback. В результате получится, что если клиент медленный, то весь этот считанный контент зависнет в памяти до того, как клиент его получит.
А что если у нас таких медленных клиентов много? А если файл очень большой? Получается, что сервер почти мгновенно может занять всю доступную память, что совершенно неприемлемо. Чтобы такого не происходило, мы заменим код отдачи файла на принципиально другой, использующий потоки. Мы уже умеем читать из файла при помощи ReadStream:
var file = new fs.ReadStream('big.html');
Это будет входным потоком данных. А выходным потоком будет объект ответа res, который является объектом класса http.ServerResponse наследующим от stream.Writable.
Общий алгоритм использования потоков для записи сильно отличатся от того, что мы рассматривали ранее. Он выглядит так:
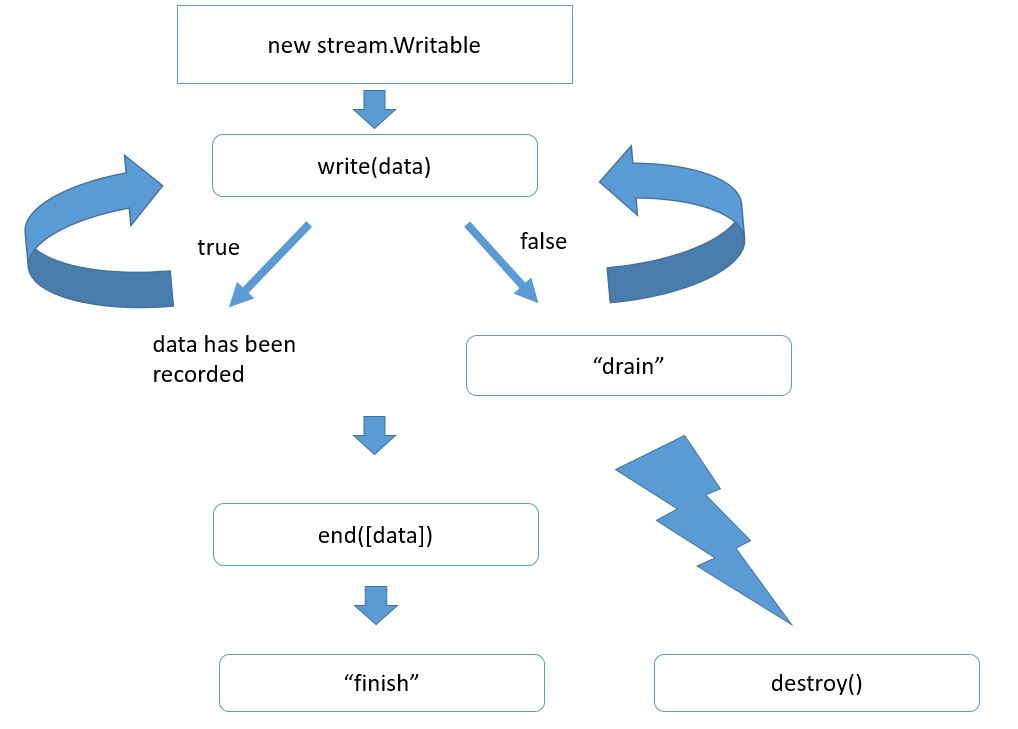
Вначале мы создаем объект потока. Если у нас http сервер, то этот объект уже создан. Это res. Дальше мы хотим отправить что-то клиенту. Это можно сделать вызовом res.write и передать там наши данные. Обычно это либо буфер, либо строка. Наши данные при этом добавляются к специальному свойству потока, которое называют его буфером. Если пока этот буфер не очень большой, то данные прибавляются к нему, и write возвращает true, что означает, что мы можем писать еще. При этом обязательство по отсылке данных берет на себя уже сам поток. Как правило, эта отсылка происходит асинхронно.
Возможен и другой вариант. Например, если мы передали сразу очень много данных, или если буфер уже был чем-то занят, то метод write может вернуть false, который означает, что внутренний буфер потока переполнен и прямо сейчас запись, конечно, можно сделать, но это будет нецелесообразно, потому что в буфере все будет копиться. Поэтому при получении false обычно запись не продолжают, а ждут специального события drain, которое будет сгенерировано потоком, когда он все отошлет, то есть, когда его внутренний буфер опустеет.
Таким образом можем вызывать write много раз, и когда мы понимаем, что все данные записаны, то мы должны вызвать метод end. Тут тоже можно передать с первым аргументом данные. В этом случае он просто вызовет write . Самая главная задача end – это закончить запись. Поток это делает, при необходимости вызывает внутренние операции закрытия ресурсов (файлов), соединений и т.д. И потом генерирует события finish, который означает, что запись полностью завершена.
Обращаем ваше внимание, что аналогичное событие у stream.Writable называется end. Это различие неслучайно, потому что есть потоки duplex, которые умеют и читать, и писать. Соответственно, они могут генерировать как одно событие, так и другое.
Поток в любой момент можно разрушить вызовом метода destroy(). При вызове этого метода работа потока прекращается, и все ассоциированные с ним ресурсы будут освобождены. Конечно, событие finish уже никогда не состоится, потому что это уже успешное окончание работы потока, успешная отдача всех данных.
Реализуем правильную отдачу файла, используя схему справок как шпаргалку. Будем делать то в отдельной функции, которая будет называться sendFile.
Она будет принимать один поток для файла и второй поток для ответа.
Для начала pipe.js будет выглядеть так:
var http = require('http');
var fs = require('fs');
new http.Server(function(req, res) {
// res instanceof http.ServerResponse < stream.Writable
if (req.url == '/big.html') {
var file = new fs.ReadStream('big.html');
sendFile(file, res);
}
}).listen(3000);
function sendFile(file, res) {
file.on('readable', write);
function write() {
var fileContent = file.read();
res.write(fileContent);
}
}
Первое, что мы будем делать с такой функцией – это ждать данных:
function sendFile(file, res) {
file.on('readable', write);
Затем, когда они получены, то внутри обработчика readable читать их и отправлять в ответ:
function write() {
var fileContent = file.read();
res.write(fileContent);
}
Конечно же, она не выдерживает никакой критики, поскольку в том случае, если клиент пока не может получить эти данные (например, потому что у него медленная скорость соединения), то они зависнут в буфере объекта res:
res.write(fileContent)
Таким образом, если файл быстро считан, но пока не отправлен, то он займет большое количество памяти, а этого мы как раз хотели избежать. В этом небольшом коде изложен пример универсального решения этой задачи, скопируйте эту часть кода в замен ранее написанной:
function sendFile(file, res) {
file.on('readable', write);
function write() {
var fileContent = file.read(); // read
if (fileContent && !res.write(fileContent)) { // send
file.removeListener('readable', write);
res.once('drain', function() { //wait
file.on('readable', write);
write();
});
}
}
}
Мы тоже читаем содержимое из файла на событие readable, но мы не просто отправляем его вызовом res.write, а еще и анализируем, что этот вызов вернет. Если res принимает данные очень быстро, то res.write будет возвращать true. Это означает, что ветка if никогда не выполнится
if (fileContent && !res.write(fileContent)) {...}
Соответственно, мы получим read-write, read-write и т.д.
Более интересный случай, когда res.write вернул false. То есть, когда буфер переполнен, в этом случае мы временно отказываемся обрабатывать события readableна файле.
file.removeListener('readable', write);
Само по себе такое снятие обработчика не означает, что файловый поток перестанет читать данные. Нет, он будет читать данные, но дочитает их до определенного уровня, заполнит свой внутренний буфер объекта файла, и затем, так как никто не вызывает read, то этот внутренний буфер останется заполнен на определенном уровне, то есть, файловый поток что-то считает и там остановиться. Далее мы дождемся события drain
res.once('drain', function() {
file.on('readable', write);
write();
});
То есть, когда данные будут успешно отданы в ответ (означает, что мы можем принять что-то еще из файла), мы вновь показываем свой интерес в событиях readable и вызываем метод write сразу. Зачем? Просто потому что, пока мы ждали этого drain, новые данные вполне могли придти. Это означает, что имеет смысл их тут же прочитать:
var fileContent = file.read();
Вызов read вернет null в том случае, если данных нет. А если есть, то они просто будут обработаны тем же способом, о котором мы говорили раньше в if.
Получается такая вот своеобразная рекурсивная функция: считать, отправить то, что считано, при необходимости подождать drain , считать, отправить и подождать, и т.д. по циклу, пока файл не закончится.

Материалы для статьи взяты из следующего скринкаста.
