SQL, or Structured Query Language, is an indispensable tool for organizing data: while front-end frameworks like Angular, React, and Vue.js (each of them is closely tied to JavaScript: check out our JS interview questions Part 1 and Part 2!) work on the magic of interacting with a web app, SQL manages does the dirty work — ensuring that all the precious data is structured accordingly.
SQL proficiency, therefore, is crucial in many areas: analytics, data science, back-end, marketing, research — and SQL developers work on truly great projects. To become proficient in SQL, however, remote developers should really take their time to study this field — and test their knowledge via technical interviews. In this article, we will explore some of the best SQL interview questions that you can study for your next technical interview.
Theory
A broad topic like organizing data in an efficient way requires some theoretical questions — with these, you can assess your fundamental database knowledge.
1. What are the differences between SQL databases and NoSQL?
First of all, it is crucial to analyse the difference between SQL and noSQL systems. It comes down to:
- Method: SQL uses fixed schemas to set the data structure up — this is the most efficient way for structured data, but a system change can be a challenge in and of itself. With NoSQL, data can be organized more freely: the developer can structure it based on KeyValue instances, make it document- or column-oriented.
- Structure: SQL uses tables which are ideal for processing multi-row transactions (e.g. accounting systems); NoSQL utilizes key-value pairs/document-based method/graph databases/wide-column stores.
- Scaling: while SQL is optimally scaled vertically (i.e. increasing the capabilities of a single server via upgrading its RAM or processing power), NoSQL prefers horizontal scaling (i.e. adding additional servers and sharding thanks to them); NoSQL, therefore, can handle large/volatile data sets better.
2. How are DDL, DML, and DCL used?

These terms encompass different SQL commands which are used, as their names suggest, to either define, manipulate, or control data.
- DDL: The Data Definition Language is used to define the database and schema structure by using a set of SQL Queries like
CREATE, ALTER, TRUNCATE, DROP, andRENAME. - DCL: The Data Control Language is used to control user access to the database via a set of commands like
GRANTandREVOKEin the SQL Query. - DML: The Data Manipulation Language is used for maintaining the data by using SQL Queries like
SELECT, INSERT, DELETEandUPDATE.
These are the DDL commands available in SQL:
CREATE: creates a new table, a view of a table, or other object in database.ALTER: modifies an existing database object, such as a table.DROP: deletes an entire table, a view of a table or other object in the database.TRUNCATE: removes all records (and spaces associated with them) from a table.COMMENT: adds comments to the data dictionary.RENAME: renames an object.
These are the DML commands available in SQL:
SELECT: retrieves certain records from one or more tables.INSERT: creates a record.UPDATE: modifies records.DELETE: deletes records.MERGE — UPSERToperation: MERGE statements are used toINSERTnew records orUPDATEexisting ones.CALL: calls a PL/SQL, or Java subprogramEXPLAIN PLAN: interprets data access path.LOCK TABLE: utilizes Concurrency Control.
These are the DCL commands available in SQL:
GRANT: gives a privilege to user.REVOKE: takes privileges granted from user back.
3. What does database transaction mean?
In a database, transactions are logical units which are executed independently to retrieve data or update it. In relational databases, the ACID acronym is used to denote the qualities of database transactions: Atomic, Consistent, Isolated, and Durable.
4. Why are relational databases difficult to scale?
One of the requirements of relational databases is support for ACID transactions; as mentioned earlier, C denotes Consistency — this means that in case of disconnected nodes all transactions will be refused. According to the CAP theorem, it is impossible for a distributed data store to provide all of these features:
- Consistency.
- Availability.
- Partition tolerance.
When an incident like network failure occurs, a distributed system can either:
- Stay online and carry on with accepting writes — this may render data inconsistent (preserving availability)
- Stop accepting writes and try to keep data stream consistent (preserving consistency)
Due to the nature of relational databases, option B is optimal. With scaling, the chance of partitioning (i.e. nodes failing to communicate) increases, resulting in the dilemma described above.
5. How can we make them scale better?
To scale relational databases effectively, we need to examine how the data is modeled: for instance, in a normalized database with heavily inter-related data, sharding becomes increasingly difficult. In essence, the problem of scaling is dependent on our application’s capacity to be divided into components/clusters. Major companies are all trying to address this issue: Oracle and MySQL provide tools for scaling, Postgres offers some extensions, and Google even created a database service that, as the company claims, is built for the cloud specifically to combine the benefits of relational database structure with non-relational horizontal scale.
There are a few solutions to the scaling problem (although they are not perfect):
- Using master-slave partitioning, we can commit every write to a single master node; the node then distributes updated data to read-only slaves. However, write operations will not be sped up — this is a crucial caveat as they are usually the bottleneck.
- Using sharding, we can store different data on different nodes: the first node, for instance, can be used to store account names, the other can store user IDs — this would move the burden of scaling higher on the stack.

6. What is Index and how it can help performance?
Indexes are database objects designed to improve query performance. By applying indexes to one or more columns in table or views, we could improve data retrieval time from these tables. Index hunting helps in improving the speed as well as the query performance of the database. This can be achieved via the following measures:
- The query optimizer is used to coordinate the study of queries with the workload and the best use of queries is suggested based on this.
- Index and query distribution along with their performance are observed to check the effect.
- Tuning databases to a small collection of problem queries is also recommended.
Coding
Now it’s time for the next group of challenges: coding! In these exercises, you can test if you’ve got what it takes to become the best remote SQL developer. (We will use MySQL syntax as it’s the most common one)
7. Write CREATE TABLE statement to create the table ‘developers’ according to the diagram
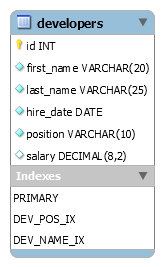
Answer:
CREATE TABLE IF NOT EXISTS `developers` ( `id` INT NOT NULL AUTO_INCREMENT, `first_name` VARCHAR(20) NOT NULL, `last_name` VARCHAR(25) NOT NULL, `hire_date` DATE NOT NULL, `position` VARCHAR(10) NOT NULL DEFAULT 'backend', `salary` DECIMAL(8,2) NULL DEFAULT NULL, PRIMARY KEY (`id`), INDEX `DEV_POS_IX` (`position` ASC), INDEX `DEV_NAME_IX` (`last_name` ASC, `first_name` ASC)) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8
8. Write a query to get monthly salary of all developers, if the table contains salaries for the year
SELECT first_name, last_name, round(salary/12,2) as 'monthly salary' FROM developers;
9. Write a query to get the maximum salary of a back-end developer
SELECT MAX(salary) FROM developers WHERE position='backend';
10. Write a query to find the 5th maximum salary in the developers table
SELECT DISTINCT salary FROM developers d1 WHERE 5 = (SELECT COUNT(DISTINCT salary) FROM developers d2 WHERE d2.salary >= d1.salary);
11. Write a query using JOIN to find the name (first_name, last_name) and hire date of the developers who were hired after ‘Wilson’
SELECT d1.first_name, d1.last_name, d1.hire_date FROM developers d1 JOIN developers d2 ON (d2.last_name = 'Wilson') WHERE d2.hire_date < d1.hire_date;
Conclusion
Organizing and structuring data may not seem “hip” or “cool” as designing modern web applications, but any SQL developer will tell you: these are just different forms of art. By the way, SQL developers might have much more power than their front-end counterparts: just look what one database error can do!