Deep Learning vs Machine Learning: Overview & Comparison


Deep Learning vs Machine Learning
The two areas of Artificial Intelligence, namely machine learning and deep learning, raise more questions than an entire field combined, mainly because these two areas are often mixed up and used interchangeably when referring to statistical modeling of data; however, the techniques used in each are different and you need to understand the distinctions between these data modeling paradigms in order to refer to them by their corresponding name. In this article, we’ll explain the definitions of artificial intelligence, machine learning, deep learning, and neural networks, briefly overview each of those categories, explain how they work, and finish with an explicit comparison of machine learning vs deep learning.
What is Artificial Intelligence?
Artificial Intelligence (hereafter referred to as AI) is the intelligence demonstrated by machines as opposed to the natural intelligence of humans. AI can be further classified into three different systems: analytical, human-inspired, and humanized artificial intelligence. Analytical AI generates the cognitive representation of the world through learning that’s based on past experiences to predict future decisions. Human-inspired AI has elements from cognitive and emotional intelligence, thus in order to predict any future decision, human-inspired AI attempts to understand human emotions in addition to cognitive elements. Humanized AI uses all types of competencies including but not limited to cognitive, emotional, social intelligence, as well as attempts to be self-conscious and self-aware of the interactions. Machine Learning and Deep Learning are two different subsets of Artificial Intelligence, which we’ll break down further below.
What is Machine Learning?
According to Wikipedia, “Machine Learning (hereafter referred to as ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without instructions, relying on patterns and inferences instead.” To put it simply, ML involves the creation of algorithms that can modify itself without human assistance to produce the desired output. Again, to simplify further: ML is a method of training algorithms so they can make decisions on their own. The intention behind ML is just as simple — enable machines to learn on their own when provided with data to make future predictions.
For example, in order to predict a storm, we have to gather the data of all the storms that have occurred in the past along with the concurrent weather conditions for a designated period of time, say six months. The task at hand: to determine which weather conditions almost certainly lead up to an upcoming storm. The results will be based on the input data that we supplied to the system. Then those results are analyzed versus the real-time conditions and the occurrence of the said storm, which can further lead to a reiteration of inputting data to polish future predictions.
How does machine learning work?
For the ML to work, special considerations need to be accounted for before applying ML to a problem. Among those are: there’s a clear pattern that would help a machine to arrive at a conclusion; there must be data readily available; the behavior can be described by a mathematical expression through a structured inference learning.
For example, the data could be multiple product reviews of one or several items, the output is the decision of whether the item is worth purchasing based on product reviews. The structured learning component is then performed by an ML algorithm to arrive at the pattern of the supplied data. The expression that the ML formulates is called the “mapping function,” which is used to learn the “target function,” that is — an expression maps the input data to output and arrives at a decision: buy an item or don’t.
So, ML performs a learning task where it makes predictions of the future (Y) based on the new given inputs (x).
Y = f(x)
To arrive at the target function (f), the prediction needs to be learned from the supplied examples (x); in our example, it tries to capture the representation of product reviews by mapping each type of review input to the output. To arrive faster to the conclusion, the algorithm considers certain assumptions about the target function and starts the estimation of that function from a hypothesis. Iterations of the hypothesis are done several times to estimate the best output.
Machine Learning Overview: summary of how ML works
The objective of ML algorithms is to estimate a predictive model that best generalizes to a set of data. For ML to be super-efficient, one needs to supply a large amount of data for the learning algorithm to understand the system’s behavior and generate similar predictions when supplied with new data.
Video Machine Learning:
Machine Learning Architecture & Development Life Cycle
Machine Learning programs operate under a lifecycle that’s different from a general software development lifecycle, meaning that the well-known app development methodologies such as agile and waterfall doesn’t work well enough with machine learning development.
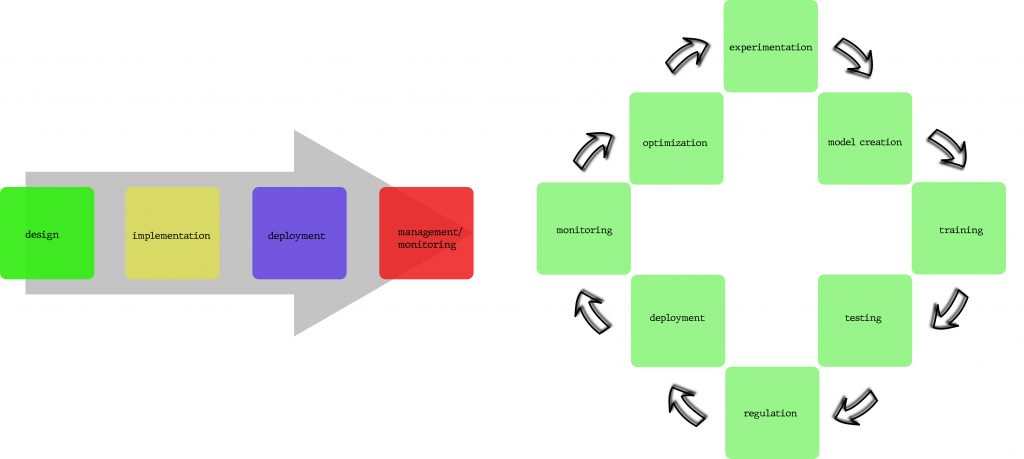
The standard app development (left) vs Machine Learning development (right)
The reason for building a separate life cycle for machine learning is primarily to support the highly iterative building, testing, and deployment of ML models. While the process of planning, creating, testing, and deploying ML models might seem similar to any other application development cycle, still there would be a lot of adaptation in order to focus on ML model evaluation and fine-tuning. The following figure represents the suggested ML adapted life cycle that guides the development professionals in implementing a continuous model deployment and control framework for automating the process of developing, testing, deploying and monitoring ML models:
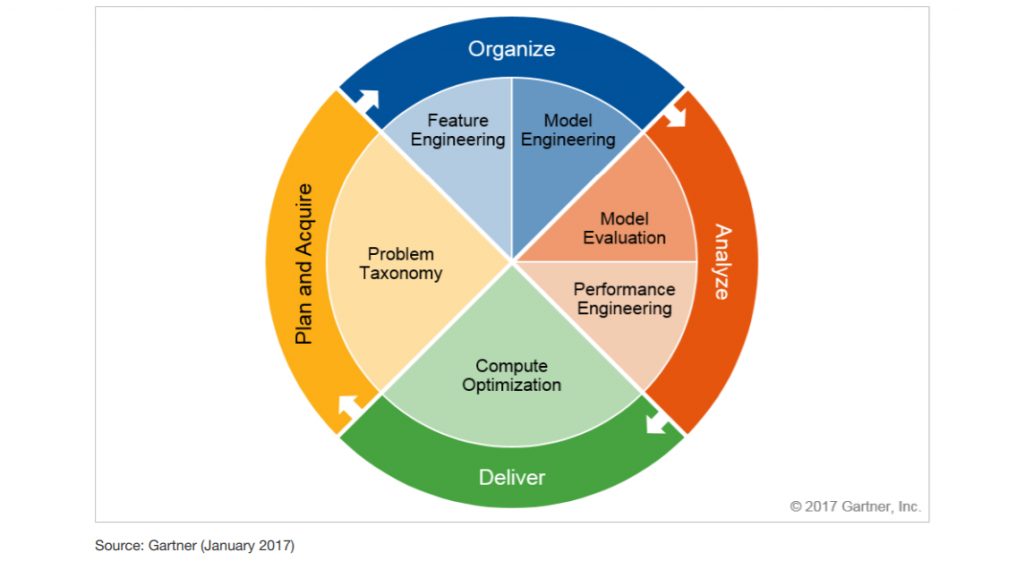
A lot of machine learning frameworks offer their own reference architectures that simplify the implementation of machine learning solutions. For example, TensorFlow’s system architecture is described in detail here, Azure ML architecture, concepts, and workflow — here.
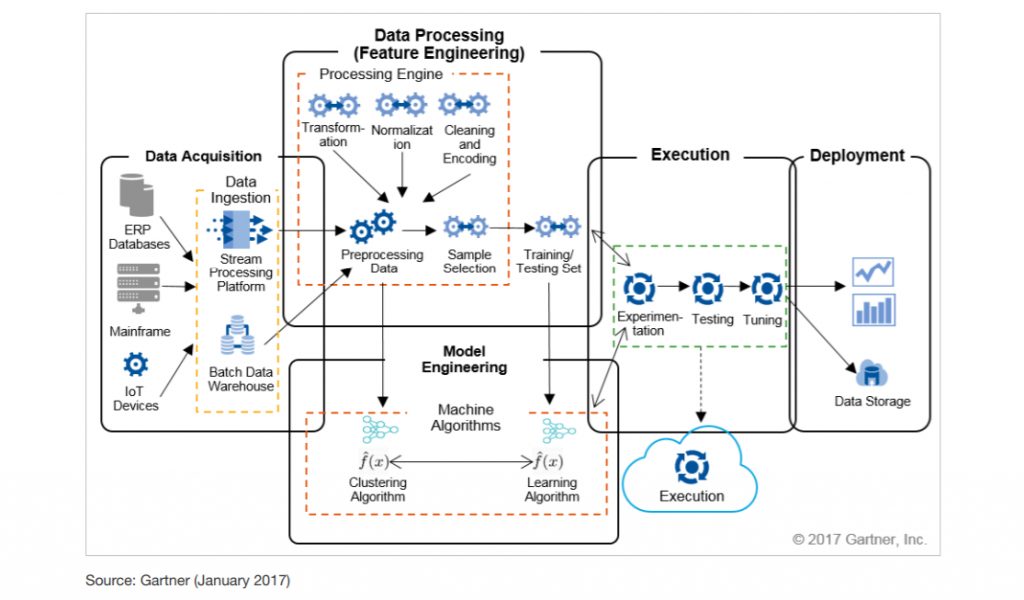
Hereinbelow is the sample of machine learning architecture, which covers the following infrastructure areas for functions needed to execute the machine learning process:
- Data acquisition, where data is collected
- Data processing, including preprocessing, sample selection, training of data sets
- Data modeling, including data model designs and ML algorithms used in ML data processing
- Execution, where the processed and trained data is forwarded for use in the execution of ML routines such as experimentation, testing, fine-tuning
- Deployment is the representation of business-usable results of the ML process — models are deployed to enterprise apps, systems, data stores.
What is deep learning?
Deep learning, on the other hand, is a subset of machine learning, which is inspired by the information processing patterns found in the human brain. The brain deciphers the information, labels it, and assigns it into different categories. When confronted with new information, the brain compares it with the existing information and arrives at the conclusion that spurs future action based on this analysis. Deep learning is based on numerous layers of algorithms (artificial neural networks) each providing a different interpretation of the data that’s been fed to them.
How does deep learning work?
Before we tackle the question of “how it works,” let’s briefly define a few other necessary terms.
Supervised learning is using labeled data sets that have inputs and expected outputs. Unsupervised learning is using data sets with no specified structure.
In the case of supervised learning, a user is expected to train the AI to make the right decision: the user gives the machine the input and the expected output, if the output of AI is wrong, it will readjust its calculations; the iterative process goes on until the AI makes no more mistakes. Among the popular supervised algorithms are linear regression, logistic regression, decision trees, support vector machines, and non-parametric models such as k-Nearest Neighbors. In the case of unsupervised learning, the user lets the AI make logical classifications from the data. Here, algorithms such as hierarchical clustering, k-Means, Gaussian mixture models attempt to learn meaningful structures in the data.
Deep Learning operates without strict rules as the ML algorithms should extract the trends and patterns from the vast sets of unstructured data after accomplishing the process of either supervised or unsupervised learning. To proceed further, we’ll need to define neural networks.
Deep Learning vs Neural Network
The Deep Learning underlying algorithm is neural networks — the more layers, the deeper the network. A layer consists of computational nodes, “neurons,” every one of which connects to all of the neurons in the underlying layer. There are three types of layers:
- The input layer of nodes, which receive information and transfers it to the underlying nodes
- Hidden node layers are the ones which take all calculations
- Output node layer is a place for computational results
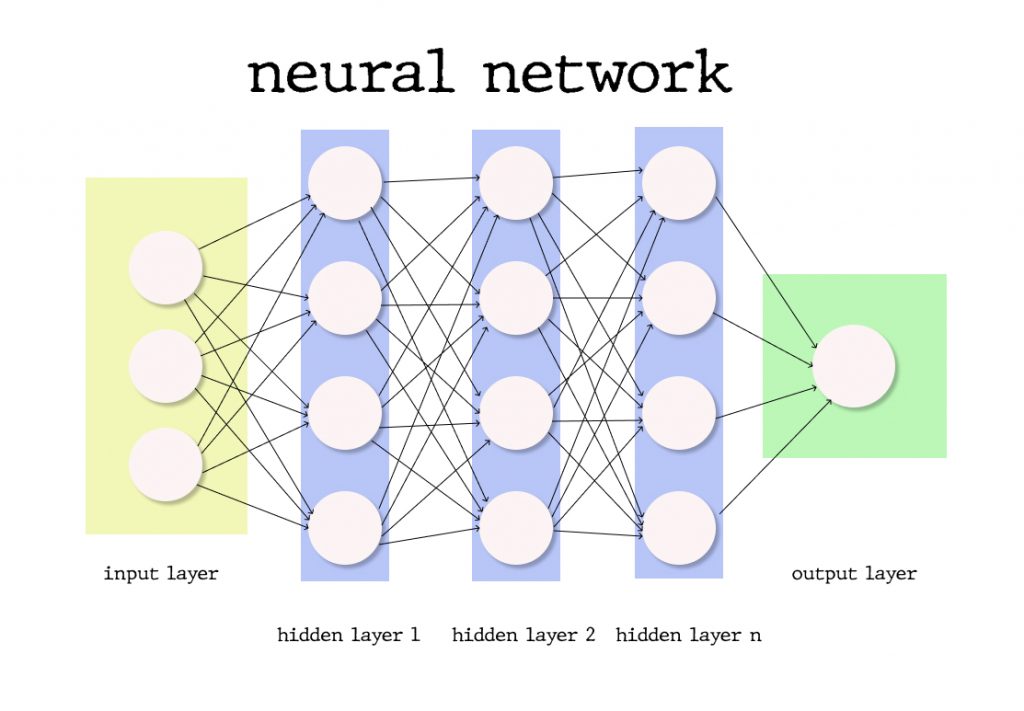
Neural Network
By adding more hidden layers into the network, the researchers enable more in-depth calculations; however, the more layers — the more computational power is needed to deploy such a network.
Each connection has its weight and importance, the initial values of which are assigned randomly or according to their perceived importance for the ML model training dataset creator. The activation function for every neuron evaluates the way the signal should be taken, and if the data analyzed differs from the expected, the weight values are configured anew and the iteration begins. The difference between the yielded results and the expected is called the loss function, which we need to be as close to zero as possible. Gradient Descent is a function that describes how changing connection importance affects output accuracy. After each iteration, we adjust the weights of the nodes in small increments and find out the direction to reach the set minimum. After several of said iterations, the trained Deep Learning model is expected to produce relatively accurate results and can be deployed to production, however, some tweaking and adjustments can be necessary if the weight of the factors change over time.
Deep learning Learning Overview: summary of how DL works
Deep Learning is one of the ways of implementing Machine Learning through artificial neural networks, algorithms that mimic the structure of the human brain. Basically, DL algorithms use multiple layers to progressively extract higher-level features from the raw input. In DL, each level learns to transform its input data into more abstract representation, more importantly, a deep learning process can learn which features to optimally place in which level on its own, without human interaction. DL is both applicable for supervised and unsupervised learning tasks, where for supervised tasks DL methods eliminate feature engineering and derive layered structures that remove redundancy in representation; DL structures that can be used in an unsupervised manner are deep belief networks and neural history compressors.
Video Deep Learning:
Deep Learning Applications
Now, let’s look at some of the top applications of deep learning, which will help you better understand DL and how it works, besides some of those offer fantastic tutorials and source code detailing how to implement those algorithms.
The most well-known application of deep learning is a recommendation engine that’s supposed to enhance the user experience and provide a better service to its users. There are two types of recommendation engines: content-based and collaborative filtering. Until you have a sizable user-base, it’s best recommended to start with the content-based engine first. Example: Keras Code for Collaborative Filtering
Natural Language Processing and Recurrent Neural Networks are used in the text to extract higher level information, also known as text sentiment analysis. Example: Twitter Sentiment Analysis
Another popular application is chatbots that can be trained with samples of dialogs and recurrent neural networks. Example: Chatbot with TensorFlow
Another popular application of DL models is image retrieval and classification using recognition models to sort images into different categories or using auto-encoders to retrieve images based on visual similarity. Example: Hacking Image Recognition
Machine Learning vs Deep Learning: comparison
One of the most important differences is in the scalability of deep learning versus older machine learning algorithms: when data is small, deep learning doesn’t perform well, but as the amount of data increases, deep learning skyrockets in understanding and performing on that data; conversely, traditional algorithms don’t depend on the amount of data as much.
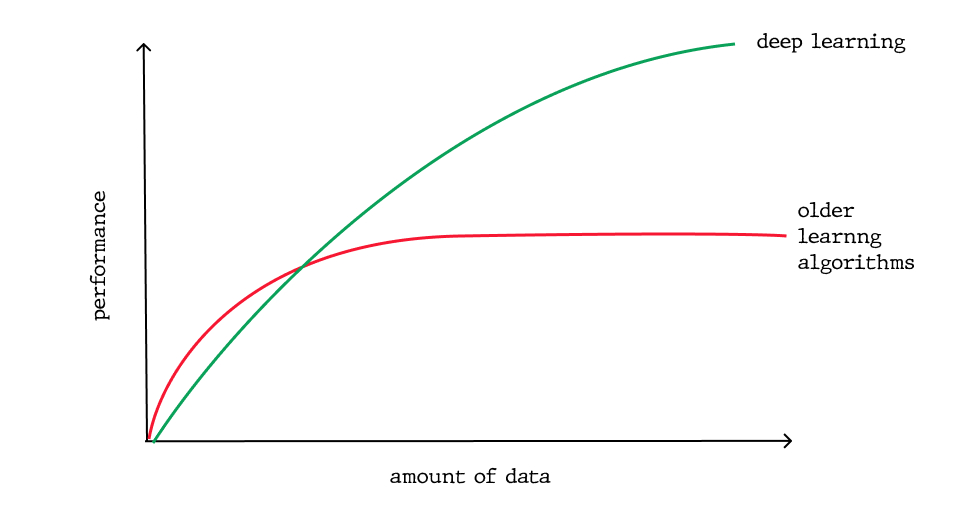
Scaling with Amount of Data
Another important distinction which ensues directly from the first difference is the deep learning hardware dependency: Dl algorithms depend on high-end machines and GPUs, because they do a large amount of matrix multiplication operations, whereas older machine learning algorithms can work on low-end machines perfectly well.
In machine learning, most of the applied features need to be identified by a machine learning expert, who then hand-copies them as per domain and data type. The input values (or features) can be anything from pixel values, shapes, textures, etc. The performance of the older ML algorithm will thus depend largely on how well and accurately the features were inputted, identified, extracted. Deep Learning learns high-level features from data, this is a major shift from traditional ML since it reduces the task of developing new feature extractor for every problem, in turn, DL will learn low-features in early layers of the neural network and then high-level as it goes deeper into the said network.
Again, because of the large amount of data that needs to be learned from, deep learning algorithms take quite a lot of time to train, sometimes as long as several weeks, comparatively, machine learning takes much less time to train to range from a second to a few hours. However, during the testing time, deep learning takes less time to run than an average machine learning algorithm.
Also, interpretability is a factor for comparison. With deep learning algorithms, sometimes it’s impossible to interpret the results, that’s exactly why some industries have had slow adoptions of DL. Nevertheless, DL models can still achieve high accuracy but at the cost of higher abstraction. To elaborate on this a little further, let’s get back to the weights in a neural network (NN), which essentially indicates a measure of how strong each connection is between each neuron. So by looking at the first layer, you can tell how strong is the connection between the inputs and the first layer’s neurons. But at the second level, you’ll lose the relationship, because the one-to-many relationship has turned into many-to-many relationships, exactly because of the high complexity of the NN nature: a neuron in one layer can be related to some other neurons which are far away from the first layer, deep into the network. Again, weights tell the story about the input but that information is compressed after the application of the activation functions making it near impossible to decode. On the other hand, machine learning algorithms like decision trees give explicit rules as to why it chose what it chose and thus, they are easier to interpret.
Further reading material:
JavaScript Machine Learning and Data Science Libraries
About the author



Top developers
-

 Alexey D. Frontend DeveloperJSReactHTMLCSSAngularShow lessAll skills
Alexey D. Frontend DeveloperJSReactHTMLCSSAngularShow lessAll skills Miodrag M. Senior React developerJSReactCSSShow lessAll skills
Miodrag M. Senior React developerJSReactCSSShow lessAll skills Dragos S. Full Stack Developer
Dragos S. Full Stack DeveloperRelated articles

 15.03.2024
15.03.2024JAMstack Architecture with Next.js
The Jamstack architecture, a term coined by Mathias Biilmann, the co-founder of Netlify, encompasses a set of structural practices that rely on ...
 19.01.2024
19.01.2024Training DALL·E on Custom Datasets: A Practical Guide
The adaptability of DALL·E across diverse datasets is it’s key strength and that’s where DALL·E’s neural network design stands out for its ...

 12.06.2023
12.06.2023The Ultimate Guide to Pip
Developers may quickly and easily install Python packages from the Python Package Index (PyPI) and other package indexes by using Pip. Pip ...
Categories



3 comments
This is also a very good post which I really enjoyed reading. It is not every day that I have the possibility to ExcelR Machine Learning Training see something like this..
Attend The Machine Learning courses in Bangalore From ExcelR. Practical Machine Learning courses in Bangalore Sessions With Assured Placement Support From Experienced Faculty. ExcelR Offers The Machine Learning courses in Bangalore.
ExcelR Machine Learning courses in Bangalore
Great Insights on Deep learning and its Comparison with Machine learning, For deeper knowledge on Deep learning training